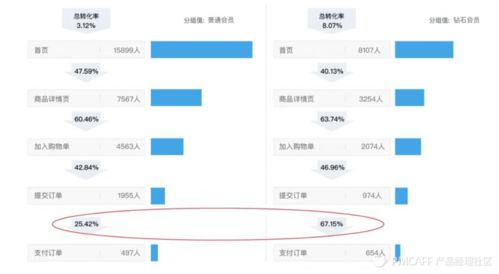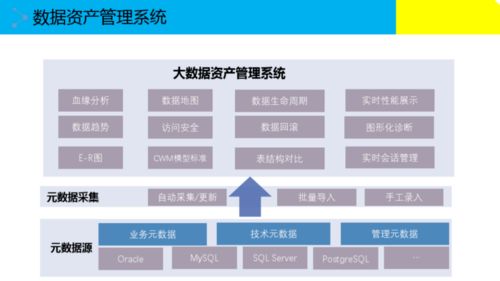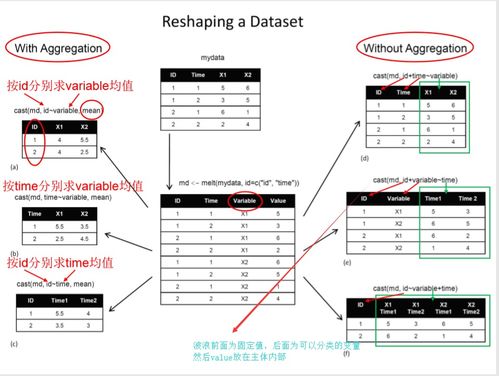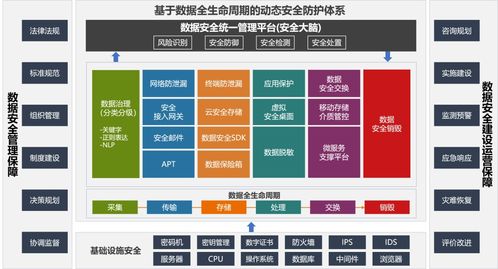
在数据驱动决策的今天,“数据工厂”作为企业数据资产生产、加工与分发的核心枢纽,其架构的先进性与健壮性直接决定了数据价值释放的深度与广度。我们再次聚焦“数据工厂”的架构升级,旨在探讨如何构建一个面向未来、高效、弹性且智能的数据处理体系。
一、从“作坊”到“工厂”:架构演进的内在逻辑
传统的数据处理模式往往呈现“烟囱式”或“作坊式”特点,流程割裂、技术栈繁杂、运维成本高昂。数据工厂概念的提出,正是为了将离散的数据任务标准化、流程化、自动化,实现从原始数据到业务洞察的“流水线”生产。其核心逻辑在于:
- 标准化输入与输出:定义清晰的数据接入规范、质量标准和交付物形态。
- 流程化与自动化:将数据清洗、转换、集成、计算、服务化等环节串联为可编排、可监控的工作流。
- 资源池化与弹性伸缩:计算与存储资源解耦,根据负载动态调配,提升资源利用率和成本效益。
二、数据处理架构升级的关键维度
本次架构升级,需围绕以下几个关键维度展开:
1. 批流一体与实时化演进
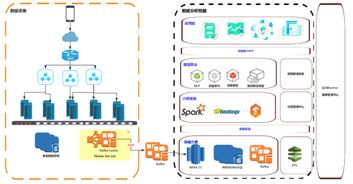
打破批处理与流处理的技术边界,采用统一的编程模型(如Flink)与执行引擎,实现同一套逻辑同时处理历史数据与实时数据流。这降低了开发运维复杂度,并使得“实时洞察”与“离线分析”结果保持一致,为实时风控、实时推荐等场景奠定基础。
2. 云原生与弹性架构
全面拥抱云原生技术栈,利用容器化(如Kubernetes)实现计算任务的敏捷部署与隔离,通过Serverless模式进一步实现细粒度资源管理和按需付费。存储与计算分离的架构,使得两者可以独立扩展,从容应对数据量与计算压力的波动。
3. 数据治理与质量内嵌
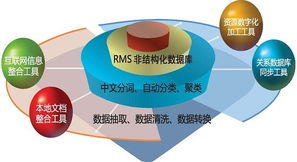
将数据治理能力(元数据、数据血缘、数据质量、数据安全)深度融入数据处理流水线。在数据加工的关键节点自动进行质量校验、敏感信息脱敏,并实时记录和可视化数据血缘,实现数据过程的可知、可控、可信。
4. 智能化运维与成本优化
引入AIops理念,利用机器学习算法对任务运行日志、资源消耗进行智能分析,实现故障预测、异常检测、根因分析与自动修复。通过对计算资源与存储成本的精细化监控与优化建议,实现数据工厂的“降本增效”。
5. 自助化与平民化数据开发
提供低代码/无代码的数据开发平台,将复杂的技术细节封装,让业务分析师、数据产品经理等角色也能通过可视化拖拽的方式,参与数据管道的设计与维护,加速数据应用的交付周期。
三、面临的挑战与应对策略
升级之路并非坦途,主要挑战在于:
- 历史负担:如何平滑迁移遗留系统与历史任务。
- 技术复杂度:新架构引入了更多组件,对团队技术能力提出更高要求。
- 组织协同:需要业务、数据、运维等多团队紧密协作。
应对策略建议采用“演进式”而非“颠覆式”的路径:
- 分域试点,价值驱动:选择业务价值高、痛点明显的领域(如实时报表)作为试点,快速验证新架构收益。
- 新旧并存,逐步迁移:构建新旧两套架构并行的双模环境,通过数据同步与任务逐步迁移,保障业务连续性。
- 能力建设与文化转型:加强团队在云原生、实时计算等领域的技术培训,并推动建立数据驱动的协作文化。
四、
数据工厂的架构升级,是一次从“技术支撑”到“价值创造”的战略转型。它不再是后台默默运行的ETL任务集合,而应进化为企业核心的、智能的、可运营的“数据中枢”。通过构建批流一体、云原生、治理内嵌、智能运维的现代化数据工厂,企业能够更敏捷地响应市场变化,更精准地驱动业务创新,最终在数据洪流中锻造出不可替代的竞争优势。数据处理能力的强弱,正日益成为区分行业领导者与跟随者的关键标尺。