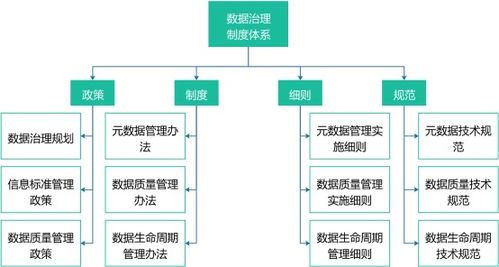
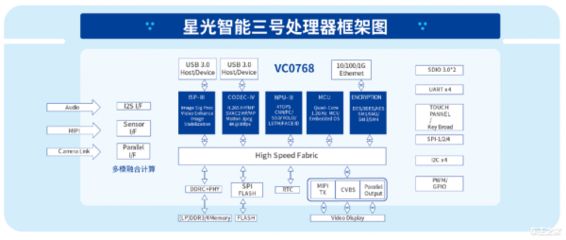
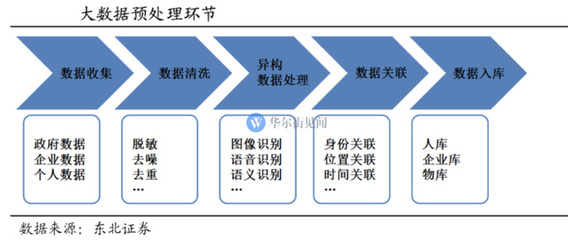
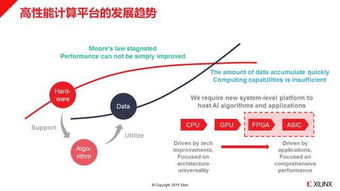
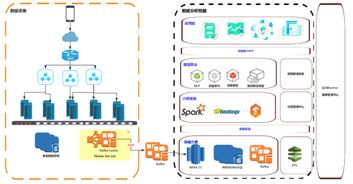
在当今这个信息爆炸的时代,企业、机构乃至个人都被海量数据所包围。数据本身并无价值,唯有通过有效的处理和分析,将其转化为可指导行动的知识,才能释放其巨大潜能。数据挖掘与商业情报处理正是实现这一转化的核心技术,它们是现代决策科学的两大支柱。
一、 数据挖掘:从数据中“挖”出模式与洞见
数据挖掘是一个跨学科的领域,它融合了统计学、机器学习、数据库技术和模式识别等方法,旨在从大型数据集(通常被称为“大数据”)中发现先前未知的、有价值的模式、趋势和关联。其核心任务可概括为以下几类:
- 分类:根据历史数据的特征,构建模型以预测新数据所属的类别。例如,银行根据客户的历史信用记录,判断新贷款申请者的风险等级(高/中/低)。
- 聚类:将数据对象分组,使得同一组(簇)内的对象彼此相似,而不同组的对象相异。它常用于客户细分,帮助企业识别具有相似购买行为的客户群体,从而制定精准营销策略。
- 关联规则学习:发现数据集中项与项之间的有趣关联。最经典的例子是“购物篮分析”,如发现“购买尿布的顾客,也常常同时购买啤酒”这一关联,从而优化货架摆放。
- 预测与回归:基于现有数据构建模型,以预测连续变量的未来值。例如,预测下一季度的销售额或股票价格走势。
- 异常检测:识别与预期模式或行为显著不同的数据点。这在金融欺诈检测、网络入侵发现和设备故障预警中至关重要。
数据挖掘的过程(如CRISP-DM模型)通常包括:商业理解、数据理解、数据准备、建模、评估和部署。这是一个迭代和探索性的过程,核心在于“发现”。
二、 商业情报处理:将信息转化为决策智慧
商业情报是一个更广泛的概念,它指的是利用技术、流程和应用来分析结构化和非结构化数据,为商业决策提供支持的系统和方法论。如果说数据挖掘是“找矿”和“提炼”,那么商业情报就是“设计蓝图”和“指挥施工”,旨在将提炼出的知识系统地应用于商业运营。
商业情报处理的核心流程包括:
- 数据整合与ETL:从分散的、异构的数据源(如ERP、CRM、社交媒体)中抽取数据,经过清洗、转换后,加载到统一的数据仓库或数据湖中,为分析提供高质量的“单一事实来源”。
- 数据存储与管理:构建数据仓库、数据集市或现代数据湖架构,高效地存储和管理海量历史与实时数据。
- 分析与报告:通过在线分析处理、即席查询、仪表盘和标准报告等形式,将数据以直观的可视化方式呈现给决策者。例如,CEO可以通过一个仪表盘实时查看全公司的关键绩效指标。
- 知识发现与决策支持:这是BI与数据挖掘交汇之处。利用数据挖掘得出的高级模型和预测结果,为战略规划、运营优化和风险管控提供深度洞察和模拟推演能力。
三、 数据处理:不可或缺的基石
无论是数据挖掘还是商业情报,其成功都建立在坚实的数据处理基础之上。数据处理是对原始数据进行的一系列操作,目的是将其转化为适合分析的、高质量的信息。关键步骤包括:
- 数据清洗:处理缺失值、纠正错误、消除重复记录和异常值。
- 数据集成:合并来自多个源的数据,解决实体识别和属性冗余问题。
- 数据转换:通过规范化、聚合、概化等方式,将数据转换为适合挖掘的形式。
- 数据归约:在尽可能保持数据完整性的前提下,缩减数据规模,以提高后续处理的效率,如通过维度归约(主成分分析)或数值归约(直方图、抽样)。
四、 融合与未来:从知识到智能行动
如今,数据挖掘与商业情报的边界日益模糊,两者正深度融合。现代BI平台(如Tableau, Power BI)已深度集成了预测分析和机器学习能力。而数据挖掘的成果也通过BI系统得以有效部署和展现,形成从“描述性分析”(发生了什么)到“诊断性分析”(为何发生),再到“预测性分析”(将会发生什么)和“规范性分析”(应该怎么做)的完整闭环。
随着人工智能、自然语言处理和自动化技术的进步,从数据中提取知识的过程将变得更加智能化、实时化和民主化。知识将不再仅仅是报告中的静态图表,而是能够主动触发业务流程、驱动自动化决策的“智能流”。掌握数据挖掘与商业情报处理的核心,意味着掌握了在数字时代将数据资产转化为核心竞争力的钥匙。